In the pair of papers on the RethinkDB web site [1] [2], RethinkDB has made a straightforward description of what they have built as a MySQL storage backend, and has alluded to a paper regarding append-only indexes which hasn't yet been posted. I'm not going to guess at what the paper includes, but I will describe what an applied theorist (like myself) would implement if given the descriptions that they provide. Note: I am unaffiliated with RethinkDB.
Overall, they have designed a database storage backend around a few primary principles regarding the performance and durability of commercially-available SSDs. 1) Re-writing an existing block of data is slow, 2) writing to an unused block is fast, 3) reading randomly is pretty fast, 4) SSDs have limited lifetimes (so writing/rewriting should be avoided as much as is reasonable), 5) the data storage system should be effectively impervious to failure, 6) recovery from failure should be essentially instantaneous, and 7) backup should be simple. They go further into the details of their testing on their blog [7], and especially into IO performance based on block size [8] and alignment [9].
Given these principles (some driving their choice, some derived from their choices), they seem to have chosen to use a persistent B-Tree to store their indexes, likely descended from the Sarnak/Tarjan paper regarding persistent search trees [3]. In particular, when writing a row to disk, they also write the B-Tree nodes that would have been modified for the indexes as well (the primary key -> row index, plus whatever other indexes are available), thus offering a "copy on write" semantic for the indexes. This is what allows for full query-able history of the database at any point in time, and works-around numbers 1 and 4, while offering 5-7, exploiting 2 and 3. The cost is that as new data and index blocks are written, a fairly large portion of previously-written data becomes historical (compared to more traditional db storage systems), and for most situations, effectively useless. This wastes space, doesn't allow for the OS to offer "TRIM" commands to the disk to free that historical data, and other annoying things.
One other issue that RethinkDB will likely run into when it starts filling disks (or contending with disks being used for more than just the DB) is write amplification; as blocks are re-used, they must be erased, and on nearly-full SSDs, a simple 4k (or 1 byte) write can result in 128-512k of data writes on the device (depending on the SSD).
To understand what is going on, and why RethinkDB uses 2 gigs to store the equivalent of 50 megs of data and indexes, we first need to look at a toy setup. Let us imagine that we have 1 million rows of data, each row consisting of two 64 bit integers; a primary key and a secondary data column. Further, there are two indexes constructed over this data; the primary key index, and an index on the data column. Given 4k block sizes, back-of-the-envelope calculations would put this at 1 million * 16 bytes for data, and an additional ~1 million * 16 bytes for each of the indexes* (ignoring some metadata and index block headers).
* Leaf nodes of the indexes are the dominant factor here, requiring the value to be indexed, as well as a pointer to the data, for 16 bytes (for a degree 256 B+Tree). Ancestors which point to leaf nodes account for a little over 1/2 of a bit for every leaf node in a full B+Tree. To keep our calculations simple, we assume as full a B+Tree as is possible on 1 million nodes.
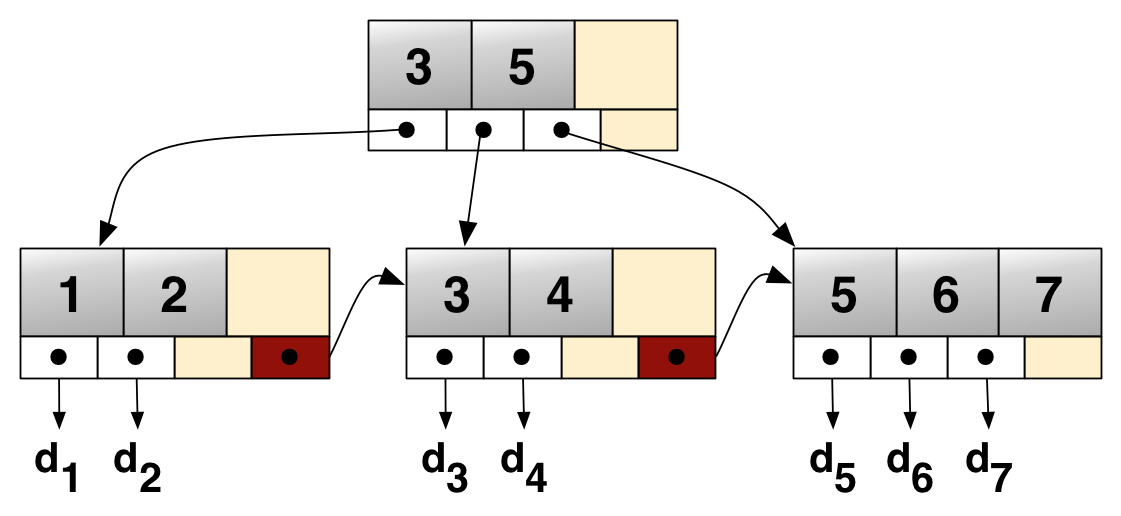
We now have a database that is 48 megs, consisting of data and indexes. Let's update every key in the database by adding a random integer value to the data column. For each update, we need to write the new row, update the primary key index to point to the new data row, and update the data index. In order to update each index, we must copy and update all ancestors of the leaf node in the B+Tree node we update. To understand why, see the image below.

Ignoring sibling pointers (the d1/d2 block pointing to the d3/d4 block *), in order to write a new d3/d4 block to point to a new d3, we must write a new root block to point to the new d3/d4 block. For a full tree of 1 million data pointers, the tree is 3 nodes deep, so we must write 3 new nodes for each B+tree index. We'll give this tree the benefit of the doubt, and say that our increments of the data index are small enough so that, for example, d3/d4 swap places, instead of having d3 migrate to the d1/d2 block. This still results in 6 block updates for every updated row, even if we assume we can find a place for the new data row of 16 bytes somewhere.
* We can alter the B+Tree format to not have sibling pointers, knowing that any traversal of the index itself will necessarily keep context about the path used to arrive at any block.
After 1 million updates, we will have updated 6 million 4-kilobyte blocks, for a total of 24 gigs of data written to update the index and data. In a standard database, while more or less the same volume of data would have been written to disk, it would have over-written existing blocks on disk (modulo a transaction or intent log), and would still only use around 48 megs of data.
Reducing Data Writes, Part 1
Because of the read-only nature of the persistent search trees, effectively all updates to the database are transient; data and indexes will be later replaced with some other write. To reduce wasted space, we should minimize the total amount of data written, which will also minimize the amount of wasted space later. First, let's reduce the amount of data we write to the index itself, by reducing the size of a logical index block from 4k. This will result in a deeper tree, but because we can store multiple tree nodes in a single 4k disk block, we can end up updating fewer disk blocks per index update.
To get an idea of how far this can go, instead of using B+Trees, let's start with a standard binary tree: 64 bit key, 64 bit data pointer (we'll leave our data pointers internal to the tree), 64 bit left/right pointers, for 32 bytes per tree node. A balanced tree with 1 million nodes is 20 levels deep, which is 640 bytes of index that needs to be updated for every row update for each index. Heck, we could fit 6x index updates in a single 4k block if we used a binary tree... at the cost of requiring potentially 20 IOs per index lookup to determine our row pointer (10 with caching, based on random tree traversals), vs. 3 for a B+Tree (or 1-2 with caching).
Let's find a balance between a 4k block and a 32 byte block; 512 bytes. If we squeeze our index into a single 64 bit value, combined with a 64 bit pointer, a B+tree index with 512 byte blocks would be 4 levels deep for our 1 million rows. Those 4 index blocks of 512 bytes would be 2k, with the data index taking up the second 2k. Assuming we could find a place for the 16 bytes of data somewhere, those 1 million row updates now only use 4 gigs of storage instead of 24 gigs, and will generally result in 2 IOs when using 16k of cache for each index.
Reducing Data Writes, Part 2
On the one hand, not having or using a transaction log is very useful, it reduces IO, and makes recovery trivially easy: your database is your transaction log. But let's bring it back, and let's do something crazy: let's either put it on a spinnning disk so we don't worry about writing 16 bytes + metadata to the end of a file whenever we want, or let's put it on an inexpensive flash drive that we write and clear in cycles (alternating between a few of them, to allow for replacement over time), and only ever write full blocks. Let's also include arbitrary "checkpoint" regions (which I'll describe more later). We'll assume that we're using ZFS with RAIDZ, a RAID 5 array, or some other storage setup where we can rely on the data not being corrupted, while still offering high write throughput. This is our append-only log.
Whenever we have a row update/insert/delete, instead of modifying the main SSD database, let's instead merely append the modification we want to perform (row with primary key X becomes Y, insert row Y with primary key X, delete row with primary key X, etc.), along with a pointer to the most recent checkpoint, to our append-only log. Our database engine will keep a cache of all of the rows that have been changed, and for any index rows that we would have updated (as is necessary during writes), we'll instead update them in-memory, without flushing them to disk.
After a fixed number of inserts/updates/deletes, or after a fixed amount of data has been written to the disk (say 1000 rows or 1 meg of data, whichever comes first, which should be tuned on a per-system basis), we dump our row updates and our updated indexes to the SSD with a checkpoint block, and append a new checkpoint to the append-only log.
Whenever the system starts up (on failure, or otherwise), it finds the most recent checkpoint in the append-only log, reads all valid operations after that checkpoint, and replays them as if they were just happening. By tuning the number of rows/maximum amount of data, we can tune the level of pain we are willing to suffer at system startup. With the provided 1000 rows or 1 meg of data, even with 512 byte blocks, that is 8000 index read IOs on the SSD to re-play the worst-case log size, which is under 2 seconds on a modern SSD. Reading 1 meg of data from our append-only log on a spinning disk whould be on the order of 10-30 ms, depending on the latency of our initial seek (assuming a non-fragmented file).
What is to be gained with this append-only log? After 1000 updates, we reduce the number of root node copy/writes from 1000 to 1. With 512 byte blocks, we also reduce second level block updates from 1000 to 32. Third and fourth level block updates may also be reduced, but we won't count those. That takes us from 1000 4k writes down to 533 4k writes, or really 4megs down to ~2.3 megs. What if we had stuck with 4k index blocks? Root node copy/writes go from 1000 to 1, second-level updates go from 1000 to 256. Overall, from 6000 4k writes to 2514 4k writes, or 24 megs to 10 megs. Remember, this is for 1000 writes, we'll scale them back up in a minute.
There is a larger proportional difference for the 4k blocks because there are only 3 levels of index, the first of which gets writes reduced by a factor of 1000x, the second which gets reduced by a factor of 4, the third we don't count. For 512 byte blocks, we get the same 1000x reduction in the root, a better 32x reduction in the second level, but no reduction in the 3rd and 4th levels.
Over the course of those 1 million rows, using this second method on 512 byte blocks, we go from the non-append log 4k block writes of 24 gigs, down to 2.3 gigs, for a factor of better than 10x reduction in data writes to our SSD.
This example was chosen specifically to maximize the ratio of index to data to show effectively worst-case performance on a toy example. As your data columns grow relative to your index columns, index updates are reduced for insert/update/delete operations. Generally speaking, we are able to get a 10x or better reduction in data write overhead by combining smaller block sizes with an append-only log file for this toy example. Real-world use-cases will have different improvements.
Reclaiming Wasted Space
During the course of writing data to the SSD for inserts/updates/deletes, index blocks will become unused (as they are no longer being referenced by the newest index nodes). Assuming that we are using both earlier described optimizations, whenever we write a checkpoint to the append-only log file, we can include the current number of wasted index blocks. When applying the updates to create a new checkpoint, any time we are replacing an existing index block, we increment the wasted index block count, and after performing all of our updates, write the wasted index block count as part of the checkpoint.
Remembering our update of the d3/d4 block from before, when we replace the d3/d4 block, we increment the count by 1, and because we need to update the root as well, we increment the count by 1 again. Generally, this will be the depth of the B+Tree, except in merging nodes and some cases of splitting nodes.
Now that we know how much wasted space we have, and we also know the size of our database file (this is trivially monitored during runtime and during startup). Whenever we get to a point where we have too much wasted space, we can reclaim that wasted space as follows.
1. Disable checkpointing in the main process. This prevents us from having to re-apply the same set of operations on two SSD database files (thus reducing our wasted space and writes to the SSD).
2. In a second process, first copy all of the standard database metadata, then for each table, traverse our primary key index for that table, and write to the a new database file, alternating writing data and index blocks (write all the data for a leaf node in the index, then write that index leaf node, etc.). In the case of 512 byte blocks, we batch up 8 (or more) data or index blocks to fill our disk block.
3. Continue in the second process to copy all other B+Tree indexes.
4. Signal to the main process that the copy has completed.
5. In the main process, when there are spare cycles, re-apply all of the changes in the append-only log file to the new db in-memory (as per Part 2 above). Optionally pre-cache hot rows what is in the old database cache.
6. When all of the updates have been performed for the new database file (in memory), perform an atomic filesystem move (discarding the old database file), discard the old database's index cache (from Part 2 above), and discard all other cache.
7. Re-enable checkpointing.
At the point of step #7, the new database file will have everything the old database file had, serving as an online VACUUM. During this VACUUM operation, system failure is not catastrophic. At any time before step 5, we can discard the secondary db file. At any time on or after step 5, restarting the database can use the new database file instead of the old, thus minimizing wasted work.
If we have a database system with relatively low amounts of memory, large amounts of writes, and the memory used by the index cache (from Part 2 above) grows too large, the first process can internally apply a checkpoint to the SSD database (which may fragment the new database file), but not update the append-only file with checkpoint information. The copying process can then ignore any data written to the main DB file after it has started with it's VACUUM, and the main process just needs to work a little harder in step 5.
In Closing, and Other Notes
I hope that you have a better understanding about the kinds of enhancements that could be done to improve a database storage system to make something like RethinkDB work as well as it does. I'm guessing that they are using at least one or two ideas described in this post, and I hope that this post gets other people thinking about ways to make such a system even better. After having seen the performance numbers for a tuned SSD system (flash, drive controller, drive-level caching, kernel drivers, os-level caching, and application), it makes the current 10k Iops numbers for consumer-level devices look like a kids toy. That RethinkDB is looking for people with heavy DB and kernel experience makes me believe that they will have a great product soon.
Incidentally, after outlining the content of this post, and between writing Part 2 and Reclaiming Wasted Space, I noticed that SQLite 3.7.0 had been released [5], which includes support for WAL files [6]. The WAL file in SQLite 3.7.0 is the rough equivalent of the append-only log that I describe in Part 2, and is more or less an Intent Log [10] in the world of database systems.
EDIT on Nov. 25, 2014: While looking around for some related information, I went digging through the RethinkDB blog and ran into this post describing methods very similar to what I described above for reducing data writes. And since this post was published in August 2010, RethinkDB is no longer a better backend for MySQL, but a distributed non-relational json-document database.
References


{kind=link}